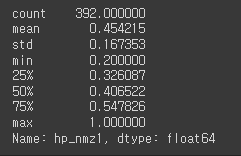
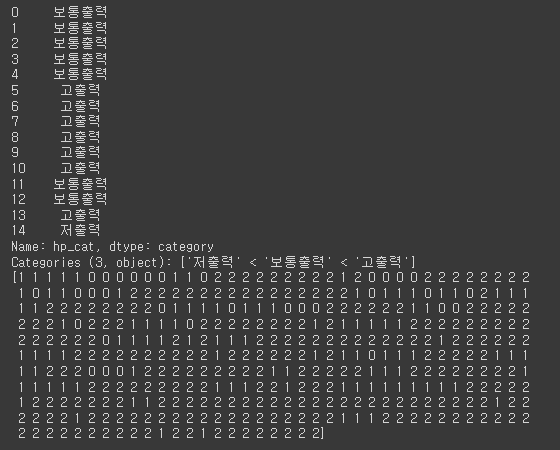
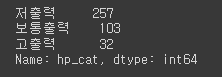
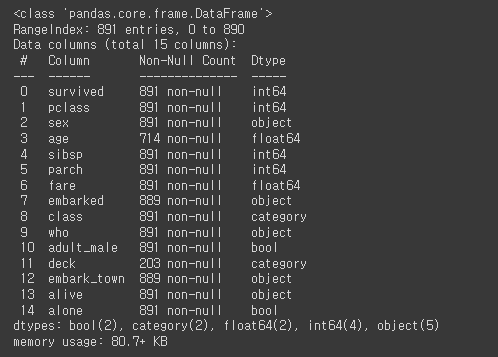
최대절대값 정규화 = 관측치 / 절대값(최대값) => -1 ~ 1 사이의 값을 가질 수 있음 df['hp_nmz1'] = df['horsepower']/abs(df['horsepower'].max()) # df['hp_nmz1'] = df['horsepower']/abs(df['horsepower']).max() df['hp_nmz1'].describe() 최소값 - 최대값 정규화 = (관측치 - 최소값) / (최대값 - 최소값) 관측치 = 최소값이라면? => 0 관측치 = 최대값이라면? => 1 => 0 ~ 1 사이의 값을 가질 수 있음 df['hp_nmz2'] = (df['horsepower'] - df['horsepower'].min())/ \ (df['horsepower'].max() - df['..