사이킷런으로 가변수를 만들어보자.
# 라벨 인코딩
[Label Encoding]
라벨 인코딩은 n개의 범주형 데이터를 0부터 n-1까지의 연속적 수치 데이터로 표현
소 → 0 / 중 → 1 / 대 → 2
주의할 점은 인코딩의 결과가 수치적인 차이를 의미하진 않는다는 것
즉, 대(2)가 중(1)의 두배라는 것은 아님!
# 사이킷런으로 더미변수 만들기
from sklearn import preprocessing
# 전처리 엔코더 객체
label_encoder = preprocessing.LabelEncoder()
onehot_encoder = preprocessing.OneHotEncoder()
# 문자열 범주를 숫자 범주로 변환 = LabelEncoder
labels = label_encoder.fit_transform(df['hp_cat'])
print(df['hp_cat'][:15])
print(labels)
# 고출력 - 보통출력 - 저출력 (글자 순서대로 정렬)
# 0 - 1 - 2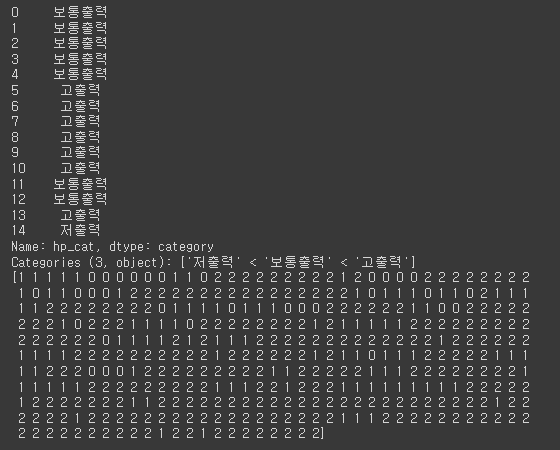
전처리 엔코더 객체를 생성한 후 문자열 범주를 숫자 범주로 변환하면 된다.
# 원핫 인코딩
[One-Hot Encoding]
n개의 범주형 데이터를 n개의 비트(0, 1) 벡터로 표현
서로 다른 범주 데이터는 독립적인 관계라는 것을 나타낼 수 있음
[주의할 점]
1. 판다스의 시리즈가 아닌 numpy 행렬을 입력해야함 → values 이용
2. 벡터 입력을 허용하지 않음 → reshape을 이용해 Matrix로 변환 필요
# 1차원 배열을 2차원 배열로 변환 => 392개의 행과 1개의 열
reshaped = labels.reshape(len(labels), 1)
print(len(reshaped))
-----------------------------------------------------------------------
# 모든 행 = -1
reshaped = labels.reshape(-1, 1)
print(len(reshaped))
원핫 인코딩을 적용해보자
# 원-핫 엔코딩
# 희소행렬 = (행, 열) 좌표 & 값(1)
# 0 숫자 열 = 고출력, 1 숫자 열 = 보통 출력 , 2 숫자 열 = 저출력
# (14, 2) 1.0 => 행 인덱스 번호 14에서 2 라는 숫자(저출력) 가지고 있는 열의 값이 1
# = 14번 행의 값은 저출력
oh = onehot_encoder.fit_transform(reshaped)print(df['hp_cat'][:15], labels[:15], oh[:15])
0 숫자 열 => 고출력 / 1 숫자 열 => 보통 출력 / 2 숫자 열 => 저출력
원핫 인코딩은 행렬로 변환한 후
결과를 확인해보면
맨 밑의 값 (14, 2) 1.0의 의미는 행 인덱스 번호 14에서 2라는 숫자(저출력)을 가지고 있는 열의 값이 1이다
라는 의미를 가지고 있다.
원핫인코딩 한 결과의 타입을 확인해보면 희소행렬이 나옴을 확인할 수 있다.
type(oh)
'Python > [개념 및 문법]' 카테고리의 다른 글
| [python] 반복문에서의 continue (0) | 2023.06.20 |
|---|---|
| [판다스] 시계열 객체 변환, 시계열 데이터 만들기, 날짜 데이터 분리, 날짜 인덱싱 (0) | 2023.06.19 |
| [python] 정규화(최대절대값 정규화, 최소값-최대값 정규화) (1) | 2023.06.19 |
| [Pandas] 데이터 구간별 범주화 pd.cut, pd.get_dummies (0) | 2023.06.19 |
| [Pandas] 데이터 전처리(널값 확인 및 대체, 중복 데이터, 표준화) (2) | 2023.06.19 |