# 문자열을 숫자로 변환
df['horsepower'] = df['horsepower'].astype('float')
# 숫자를 범주형으로 변환
df['origin'] = df['origin'].astype('category')
df['origin'].dtypes
구간 분할- cut
범주형 변환
# 범주형 변환bins_name = ["저출력", "중간출력", "고출력"]
df['hp_cat'] = pd.cut(x = df['horsepower'], # 데이터 = 사용할 열
bins = bins, # 구간의 값
labels = bins_name, # 구간의 이름
include_lowest = True) # 구간의 시작값 포함
# 1차원 배열을 2차원 배열로 변환 => 392개의 행과 1개의 열labels.reshape(len(labels), 1)
# 모든 행 = -1reshaped = labels.reshape(**-1**, 1)
사이킷런 - OneHot Encoding
# 원-핫 엔코딩# 희소행렬 = (행, 열) & 값(1)# 0 숫자 열 = 고출력, 1 숫자 열 = 보통 출력, 2 숫자 열 = 저출력# (14, 2) 1.0 => 행 인덱스 번호 14에서 2 라는 숫자(저출력) 가지고 있는 열의 값이 1# = 14번 행의 값은 저출력 oh = onehot_encoder.fit_transform(reshaped)
# 1) Timestamp로 먼저 변환해야 함dates_ts = pd.to_datetime(dates)
# 2) Period 로 변환
dates_ts.to_period(freq = 'D') # 연월일
dates_ts.to_period(freq = 'M') # 연월
dates_ts.to_period(freq = 'A') # 연
# Timestamp 배열 = range()sd_ts = pd.date_range(start = '2022-01-01', # 시작 날짜
end = None, # 끝 날짜
periods = 12, # Timestamp 개수
freq = 'M', # 월 간격, 월 마지막일
tz = 'Asia/Seoul'# timezone 시간대 설정
)
sd_ts
# freq = 'M' # 월 간격, 월 마지막일# freq = '3M' # 3개월 간격, 월 마지막일
-----------------------------------------------------------
DatetimeIndex(['2022-01-01 00:00:00+09:00', '2022-02-01 00:00:00+09:00',
'2022-03-01 00:00:00+09:00', '2022-04-01 00:00:00+09:00',
'2022-05-01 00:00:00+09:00', '2022-06-01 00:00:00+09:00',
'2022-07-01 00:00:00+09:00', '2022-08-01 00:00:00+09:00',
'2022-09-01 00:00:00+09:00', '2022-10-01 00:00:00+09:00',
'2022-11-01 00:00:00+09:00', '2022-12-01 00:00:00+09:00'],
dtype='datetime64[ns, Asia/Seoul]', freq='MS')
# Period 배열
sd_prd = pd.date_range(start = '2022-01-01', # 시작 날짜
end = None, # 끝 날짜
periods = 6, # Period 개수 + 1 = 날짜 개수
freq = 'M') # 월 간격print(sd_prd)
------------------------------------------------------------
DatetimeIndex(['2022-01-31', '2022-02-28', '2022-03-31', '2022-04-30',
'2022-05-31', '2022-06-30', '2022-07-31', '2022-08-31',
'2022-09-30', '2022-10-31', '2022-11-30', '2022-12-31'],
dtype='datetime64[ns]', freq='M')
날짜 데이터 분리
# Timestamp# 연 - 월 - 일 데이터에서 연, 월, 일 추출print(df['Date_new'].dt.year) # 연 추출
df['Date_new'].dt.month) # 월 추출print(df['Date_new'].dt.day) # 일 추출
# Periodprint(df['Date_new'].dt.to_period(freq = 'A')) # 연print(df['Date_new'].dt.to_period(freq = 'M')) # 월
날짜 인덱스로 인덱싱
df['2018'] # 연 => 2018년 데이터들만 추출됨
df['2018-06'] # 2018년 6월 데이터 추출됨
df.loc['2018-06', 'High': 'Low' ] # 연월 & High 열부터 Low 열까지
7. 데이터프레임 응용
개별 원소에 함수 매핑
apply : 시리즈 원소에 함수 매핑
# 사용자 정의 함수# 5를 더하는 함수defadd5(x):return x + 5# 두 객체를 더하는 함수defadd_two(a, b):return a + b
df['age'].apply(add5)
df['age'].apply(add_two, b = 3) # a : age, b = 3
df['age'].apply(lambda x: x + 5)
df['age'].apply(lambda x: add5(x))
df['age'].apply(lambda x: add_two(x, b = 3))
applymap : 데이터프레임 원소에 함수 매핑
df.applymap(add5)
print(df.applymap(lambda x : x + 5))
print(df.applymap(lambda x : add5(x)))
시리즈 객체에 함수 매핑
apply(매핑함수, axis = 0)
# 1) 반환하는 값이 여러 개인 경우# 널값에 대한 불 인덱스를 반환하는 함수defmv_find(series):return series.isnull()
# 열 단위 = 시리즈 객체
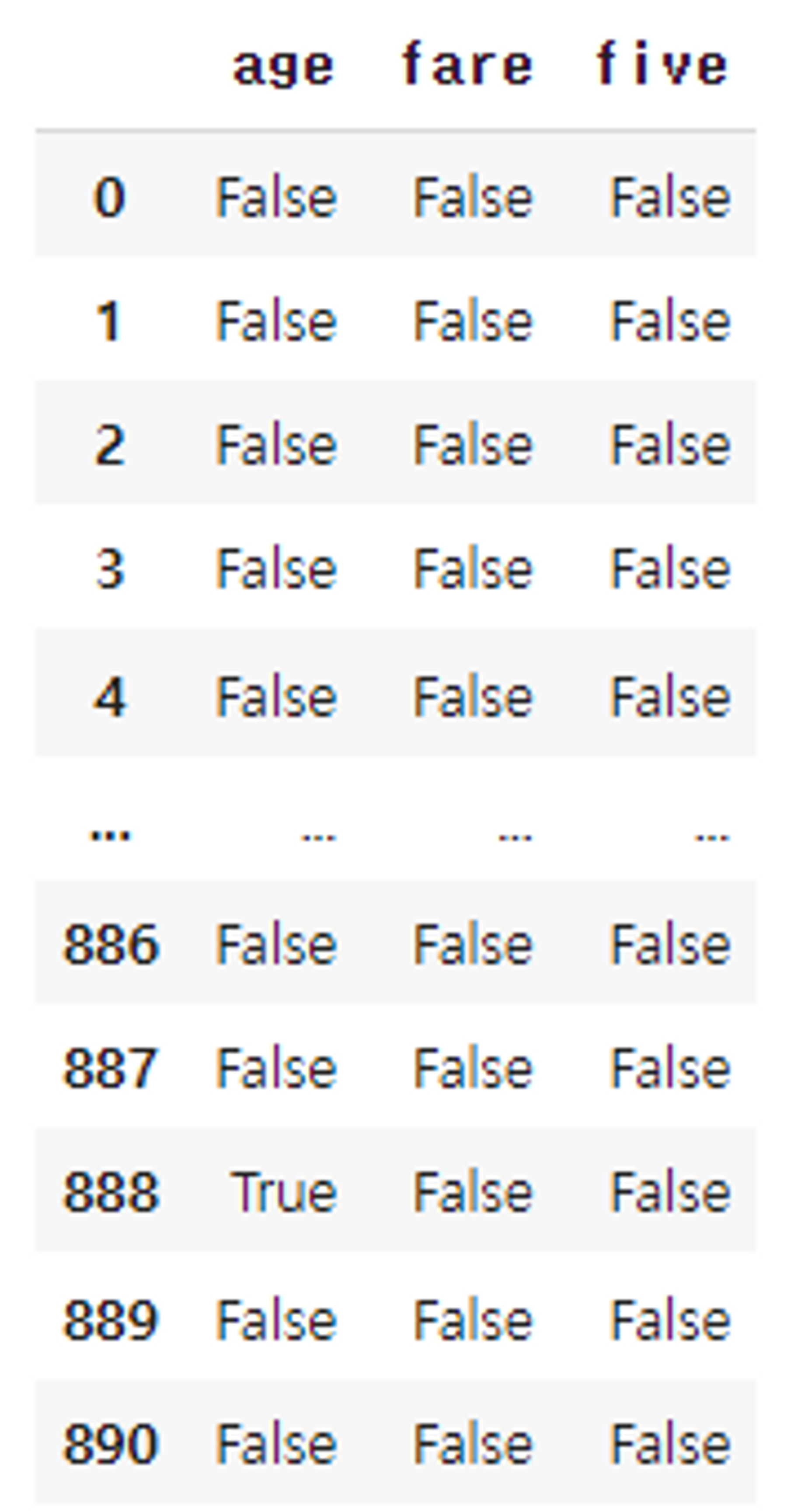
df.apply(mv_find, axis = 0)
---------------------------------------------------------------
# 2) 반환하는 값이 하나인 경우# 범위를 구하는 함수defrange_xy(series):return series.max() - series.min()
# 열 단위 = 시리즈 객체
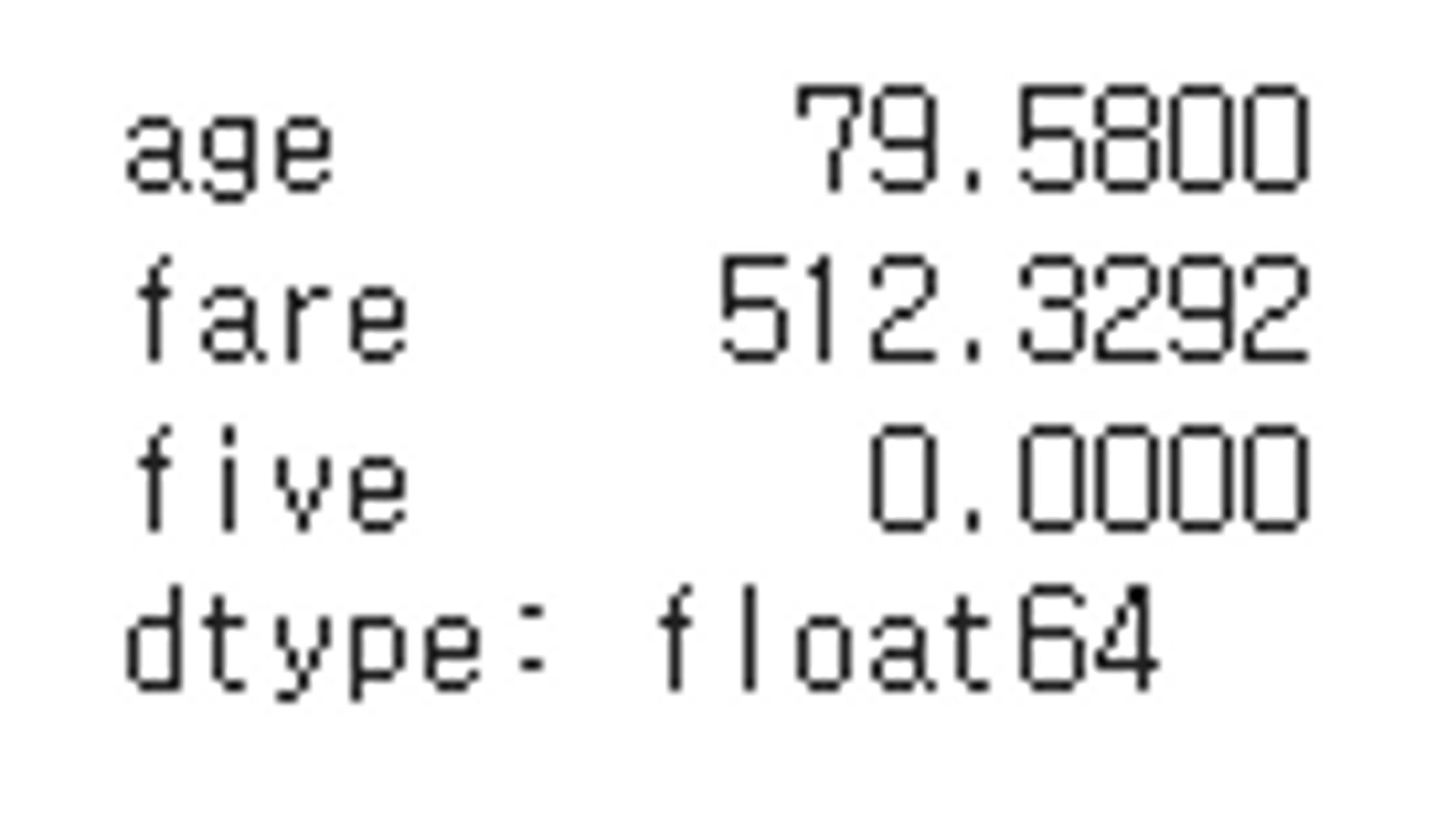
df.apply(range_xy, axis = 0)
# 행 단위
df['age_plus_five'] = df.apply(lambda x : x['age'] + x['five'], axis = 1)
df.apply(lambda x : add_two(x['age'], x['five']), axis = 1)
데이터프레임 객체에 함수 매핑
pipe(매핑 함수)
df = df.loc[:, 'age' : 'fare']df1 = df.pipe(mv_find)
# 데이터프레임 = 함수 적용된 결과는 시리즈 개수와 일치 (= 891개)defmv_count(series):returnmv_find(series).sum()
# 시리즈 = 함수 적용된 결과가 하나(열마다) = 열 개수df2 = df.pipe(mv_count)df2----------------------------------------------------------------age177fare0dtype: int64defmv_count_total(series):returnmv_count(series).sum()
# 개별값 = 함수 적용된 결과가 개별값(전체가) = 전체가 하나df3 = df.pipe(mv_count_total)df3----------------------------------------------------------------177
데이터 전처리
자료형 변환
데이터 타입 확인
# 숫자가 문자열로 저장되어 있다면 숫자로 변환 => 수치형 변수# 데이터 자료형df.dtypes
문자열 고유값 확인
# 어떤 문자열이 들어갔는지 확인하는 방법
df['horsepower'].unique()
문자열 NaN으로 변경
import numpy as np
# ? => NaN
df['horsepower'].replace("?", np.nan, inplace = True) # ? 문자열을 nan으로 변경
df['horsepower'].unique()
# 문자열을 숫자로 변환
df['horsepower'] = df['horsepower'].astype('float')
# 숫자를 범주형으로 변환
df['origin'] = df['origin'].astype('category')
df['origin'].dtypes
구간 분할- cut
범주형 변환
# 범주형 변환bins_name = ["저출력", "중간출력", "고출력"]
df['hp_cat'] = pd.cut(x = df['horsepower'], # 데이터 = 사용할 열
bins = bins, # 구간의 값
labels = bins_name, # 구간의 이름
include_lowest = True) # 구간의 시작값 포함
# 1차원 배열을 2차원 배열로 변환 => 392개의 행과 1개의 열labels.reshape(len(labels), 1)
# 모든 행 = -1reshaped = labels.reshape(**-1**, 1)
사이킷런 - OneHot Encoding
# 원-핫 엔코딩# 희소행렬 = (행, 열) & 값(1)# 0 숫자 열 = 고출력, 1 숫자 열 = 보통 출력, 2 숫자 열 = 저출력# (14, 2) 1.0 => 행 인덱스 번호 14에서 2 라는 숫자(저출력) 가지고 있는 열의 값이 1# = 14번 행의 값은 저출력 oh = onehot_encoder.fit_transform(reshaped)
# 1) Timestamp로 먼저 변환해야 함dates_ts = pd.to_datetime(dates)
# 2) Period 로 변환
dates_ts.to_period(freq = 'D') # 연월일
dates_ts.to_period(freq = 'M') # 연월
dates_ts.to_period(freq = 'A') # 연
# Timestamp 배열 = range()sd_ts = pd.date_range(start = '2022-01-01', # 시작 날짜
end = None, # 끝 날짜
periods = 12, # Timestamp 개수
freq = 'M', # 월 간격, 월 마지막일
tz = 'Asia/Seoul'# timezone 시간대 설정
)
sd_ts
# freq = 'M' # 월 간격, 월 마지막일# freq = '3M' # 3개월 간격, 월 마지막일
-----------------------------------------------------------
DatetimeIndex(['2022-01-01 00:00:00+09:00', '2022-02-01 00:00:00+09:00',
'2022-03-01 00:00:00+09:00', '2022-04-01 00:00:00+09:00',
'2022-05-01 00:00:00+09:00', '2022-06-01 00:00:00+09:00',
'2022-07-01 00:00:00+09:00', '2022-08-01 00:00:00+09:00',
'2022-09-01 00:00:00+09:00', '2022-10-01 00:00:00+09:00',
'2022-11-01 00:00:00+09:00', '2022-12-01 00:00:00+09:00'],
dtype='datetime64[ns, Asia/Seoul]', freq='MS')
# Period 배열
sd_prd = pd.date_range(start = '2022-01-01', # 시작 날짜
end = None, # 끝 날짜
periods = 6, # Period 개수 + 1 = 날짜 개수
freq = 'M') # 월 간격print(sd_prd)
------------------------------------------------------------
DatetimeIndex(['2022-01-31', '2022-02-28', '2022-03-31', '2022-04-30',
'2022-05-31', '2022-06-30', '2022-07-31', '2022-08-31',
'2022-09-30', '2022-10-31', '2022-11-30', '2022-12-31'],
dtype='datetime64[ns]', freq='M')
날짜 데이터 분리
# Timestamp# 연 - 월 - 일 데이터에서 연, 월, 일 추출print(df['Date_new'].dt.year) # 연 추출
df['Date_new'].dt.month) # 월 추출print(df['Date_new'].dt.day) # 일 추출
# Periodprint(df['Date_new'].dt.to_period(freq = 'A')) # 연print(df['Date_new'].dt.to_period(freq = 'M')) # 월
날짜 인덱스로 인덱싱
df['2018'] # 연 => 2018년 데이터들만 추출됨
df['2018-06'] # 2018년 6월 데이터 추출됨
df.loc['2018-06', 'High': 'Low' ] # 연월 & High 열부터 Low 열까지
7. 데이터프레임 응용
개별 원소에 함수 매핑
apply : 시리즈 원소에 함수 매핑
# 사용자 정의 함수# 5를 더하는 함수defadd5(x):return x + 5# 두 객체를 더하는 함수defadd_two(a, b):return a + b
df['age'].apply(add5)
df['age'].apply(add_two, b = 3) # a : age, b = 3
df['age'].apply(lambda x: x + 5)
df['age'].apply(lambda x: add5(x))
df['age'].apply(lambda x: add_two(x, b = 3))
applymap : 데이터프레임 원소에 함수 매핑
df.applymap(add5)
print(df.applymap(lambda x : x + 5))
print(df.applymap(lambda x : add5(x)))
시리즈 객체에 함수 매핑
apply(매핑함수, axis = 0)
# 1) 반환하는 값이 여러 개인 경우# 널값에 대한 불 인덱스를 반환하는 함수defmv_find(series):return series.isnull()
# 열 단위 = 시리즈 객체
df.apply(mv_find, axis = 0)
---------------------------------------------------------------
# 2) 반환하는 값이 하나인 경우# 범위를 구하는 함수defrange_xy(series):return series.max() - series.min()
# 열 단위 = 시리즈 객체
df.apply(range_xy, axis = 0)
# 행 단위
df['age_plus_five'] = df.apply(lambda x : x['age'] + x['five'], axis = 1)
df.apply(lambda x : add_two(x['age'], x['five']), axis = 1)
데이터프레임 객체에 함수 매핑
pipe(매핑 함수)
df = df.loc[:, 'age' : 'fare']df1 = df.pipe(mv_find)
# 데이터프레임 = 함수 적용된 결과는 시리즈 개수와 일치 (= 891개)defmv_count(series):returnmv_find(series).sum()
# 시리즈 = 함수 적용된 결과가 하나(열마다) = 열 개수df2 = df.pipe(mv_count)df2----------------------------------------------------------------age177fare0dtype: int64defmv_count_total(series):returnmv_count(series).sum()
# 개별값 = 함수 적용된 결과가 개별값(전체가) = 전체가 하나df3 = df.pipe(mv_count_total)df3----------------------------------------------------------------177